|
SYNTAX I
Prescriptive
Topics: Dr. Grammar
Topics
Lexical or grammatical?
Conrad
-
Most
grammar = +/- acceptable. In CL, "degrees" of acceptability
-
I
think [that] she's nice
-
has
been being V-ed
-
NP was Ved PREP by NP
-
IO (Mary, Africa)
-
require to be V-ed
-
Tie in
with functional and cognitive. Not abstract theory, like in generative
grammar.
-
Lexico-grammatical
patterns (e.g. [v*] to / [v*] that)
-
Semantic
prosody: e.g. get passive, go/come + ADJ
-
Relationship to genres: passive, perfect, progressive
-
Grammar
of speech: traditionally not covered (ELang notes)
Biber
-
Corpus -- 40 million
words (see page 8) -- spoken and written, American and British
-
Real examples
-
Coverage of language
variation (e.g. 1 | 2 pronouns vs. proper Ns; NP modification)
-
Coverage of preference
and frequency (e.g. passives)
-
Interpretations of
frequency: context and discourse
-
Dialect less important
for grammatical purposes than register
-
Issue of standard vs.
non-standard grammar (might could)
-
Prescriptive vs.
descriptive (who/whom, prep stranding, split infinitive)
Hunston: "local grammar"
(cf Construction Grammar)
-
the NOUN of the NOUN
-
the NOUN of _vvg
-
VERB that PRON
-
VERB to VERB
-
it BE * NOUN that
One construction vs. many
(Biber vs mine)
My work
Spanish/Portuguese (why infinitives):
-
Causatives (hacer, mandar, dejar, ver, oír)
-
Clitic climbing (LO quiero / deseo hacerLO)
-
Subject raising (parecer)
English
-
to V / V-ing (started to walk
/ walking) (small corpora page)
-
V-ing construction (they
talked him into going)
-
+/- for: I'd like
(for) you to put them in order
-
Linguistic Vanguard (byu_ling)
Setting up the
searches (precision / recall)
-
passive (all forms vs
are|were)
-
who / whom
-
will.[v*] vs will [v*]
-
quotative like (and I'm
like 'no way')
-
I have
not
NP
vs I don't have
NP
-
I think (that)
they'll do it
-
I saw the man (that)
you talked to
Using the corpora:
|
CHAPTER |
TOPIC |
| 3 |
Preposition stranding (He's the one
I was talking to) |
| 4 |
Pronouns and gender (he or she) |
| 5 |
Phrasal verbs: frequency of "separated"
verbs: look (up) the word (up) |
| 6 |
Can / may (can / may I use the phone?)
|
| 6 |
Passive (was studied)
|
| 6 |
Get passive (got run over (vs. was
run over)) |
| 6 |
Progressive (is watching)
|
| 6 |
Perfect (HAVE seen) |
| 6 |
Combinations of perfect, passive,
progressive (has been watching, was being considered, etc)
|
| 6 |
Future (going to verb / will verb)
|
| 6 |
Will / shall (I will / shall
consider five factors...) |
| 6 |
Semi-modals (need to , have to,
ought to, etc) |
| 6 |
Modals: frequency of different
modals |
| 7 |
Comparatives (sillier / more silly)
|
| 7 |
Go / come ADJ (go crazy, come
clean) |
| 7 |
Get ADJ(ed) |
| 8 |
Contraction (they simply cannot /
can't do it) |
| 8 |
No / not negation (I don't have any
reason / I have no reason) |
| 9 |
Frequency of [nn*] [nn*] (the
breakfast cereal ad campaign) |
| 10 |
+/- that (I guess (that) they're
not coming) |
| 10 |
begin / start + INF / V-ING
(started watching / to watch) |
| |
Like: and she's like "I'm not going out with him" |
| |
so not ADJ: I'm so not going out with her / he's so not
the kind of guy I like |
With any feature, there will be some
difference between genres, time periods, or dialects. The question
is whether this difference is statistically significant. To
determine this, you can use
chi-square. (I should mention that there are
some problems with using chi-square with the types of large
numbers that you get with these corpora. But we'll ignore that for
the time being.)
Example #1: With +/- "to" in the
construction "help someone (to) verb", the following is the data
from the BNC and COCA is:
| |
American |
British |
|
+to |
2230 |
1581 |
|
- to |
16220 |
3122 |
|
% - to |
88% |
66% |
Plugging the numbers in the four yellow
cells into the
chi-square calculator, we get a "p-value" of 0 (which
is really low, and) which is below .05. So yes, the difference
is significant.
Example #2: With "going to VERB" vs. "will
VERB" in the five genres of COCA, we get:
| |
SPOK |
FIC |
MAG |
NEWS |
ACAD |
|
will [v*] |
155791 |
67245 |
144578 |
182891 |
104482 |
|
going to [v*] |
209335 |
46999 |
26512 |
41795 |
6113 |
|
% going to |
57% |
41% |
14% |
19% |
6% |
Plugging the numbers in the ten yellow cells into the
chi-square calculator, we get a "p-value" of 0
(which is again really low, and) which is again below .05.
So yes, the differences is again significant.
Example #3: With "accustomed to [vvi]
(accustomed to watch)" vs. "accustomed to [vvg] (accustomed to
watching") in the different decades of the TIME Corpus, we get:
| |
1920s |
1930s |
1940s |
1950s |
1960s |
1970s |
1980s |
1990s |
2000s |
|
V |
36 |
64 |
23 |
10 |
6 |
11 |
5 |
5 |
2 |
|
V-ing |
17 |
31 |
38 |
48 |
32 |
44 |
30 |
28 |
8 |
|
%V-ing |
32% |
33% |
62% |
83% |
84% |
80% |
86% |
85% |
80% |
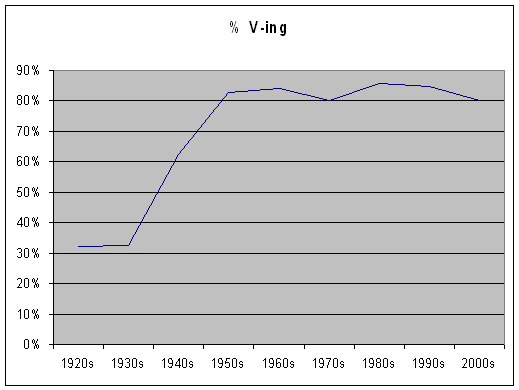
If you plug in the numbers from the
yellow cells into the
chi-square calculator, we once more get a "p-value"
of 0, which is again significant. This makes sense, because
there is a big increase in V-ing from the 1930s-1950s. But
if we just include the numbers from the 1950s-2000s, then
the p-value increases to .98, which is not below .05, and
therefore not statistically significant.
Sample research (with partner)
V that: I guess (that) they'll be here at 10 N that:
the guy (that) you saw |